Yes the settings remain the same, maybe the issue will go away when you get more scrapers.
I’m glad the tip worked,
This will give you a nice juicy block to all the scrapers.
I have another post about this topic using save posts, check it out!
I’ve replied to your exact question already, please don’t copy paste the same question it just makes the thread spammy…
If you want to add to it you can reply to it or quote a part of it.
I tagged @Adnan for a reason, so he can reply to the question.
I understand what you are saying, I just need someone to clarify this since it’s an important thing to discuss.
I am not sure about that.
1 Like
Hi @Hadi I have a question!
First of all I love your settings and this new features as it’s very smart to manage requests, anyway I still have a question.
It says that if no “scrapers” are available, it will use the “main” account:
So if without valid scraper it should works itself…but here what I don’t get.
The account is Valid, API and it says error 550 account not logged. Any hint?

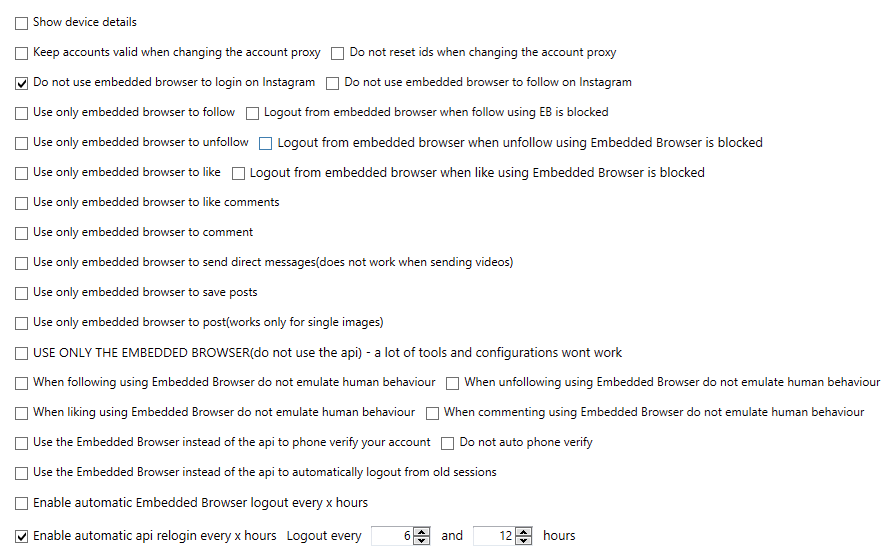
Thank you so much!
1 Like
I don’t think that what is written here is what actually happens, since we get error 550 when there aren’t any scrapers available.
Make sure you have enough scrapers too, error 550 can also mean that the scrapers are busy scraping for another account.
1 Like
Thanks man, will try!
1 Like
Let me know if it works!
Thank you @Hadi
Well, the First time your article didn’t make any sense at all.
And second, third times also made no difference.
The problem is, I wasn’t reading.
When I started reading, ‘like reading for real’, it all started making sense.
I’ve been doing 1:1 scrapers per main and I kind refilling scrapers more often as they tend to get banned a lot.
I’m going to try this and I’m sure, this will keep me from refilling scrapers for a while.
Again, Thank You for all the time and effort!
1 Like
Your welcome!
Yea this is way more efficient than 1:1 scraping.
Let me know how if this method works with you and if you run into any issues
1 Like
Yeah, I’ll be in touch.
Growing some slaves for a client and my scrpares are exhausted now.
I’m sure this is going to work.
I shall start reunning scrapers homefully tomorrow.
Again, I Thank You for all your efforts.
1 Like
Question here, if I use this method “which is a genius method” I won’t be able to use source like “like latest feed posts” or filters like “user is not following this account” am I right?
1 Like
Actually, you won’t be able to use those filters if you DON’T use this method. If your using a scraper and have the like latest feed source checked, it will use the scrapers latest feed not the main accounts.
What proxies are you using for your scrappers? I just got hit with a huge wave of captcha on all my scrappers which can’t be solved according to MP support. It’s probably because I’m running them on cheap DC proxies.
1 Like
In your experience, how many scrappers need to be set-up for main accounts?
Is 1 scraper for 2 main accounts each doing 300 actions per day is good or it may results in bloks?
Hey @Hadi, as planned I started 20 new scrapers and sorry I’m kinda lost here.
This is my situation.
Some of my main accounts already have previously scraped users in the follow sources (Follow Specific Users)
So it looked to me, whenever my main account starts to follow users, it won’t cause scrapers to fire up as the main account already have users to follow. Am I right?
So I started going after likes.
I set up my scrapers to like and configured the scraper to ‘send to extracted posts’
Then on my main account, I set up all the filters and started the like tool.
On my main account, I’m using ‘Like posts of users that interacted with posts on target accounts’ as my sources + enabled Like specific posts based on url
So that account liked 5 posts.
At the same time, I noticed the main account hit 9 API errors. (Yes, I’m running all my main accounts on API full emulation)
So I stopped the like tool.
My question is, is there a way to find that my main account liked the posts sent by scrapers or the main account itself scraped the posts and liked?
I’m sorry, I hope my question is clear.
If you need anything else to know, I’d be more than happy to answer.
Thank you
I sent you a PM
If you set it up the way I did, just look at your accounts. If your account get delayed a lot, then you need more scrapers, if you never see a delay, then you need less scrapers. This is case by case so go see how many API calls the scraper does, if it does too much, get more, if it barely does anything, get more clients.
They wont fire up if they’re using the specific users, turn it off and see if it activates the scrapers. If you already have other sources on the main account but don’t want the specific accounts to go to waste, try changing the priority value to something low.
This method does not use sending to extracted posts.
Try to relogin, check your proxy quality (don’t use DC to like), don’t have the account logged in elsewhere, export API scrape blocks and check if any say “yes”, then just wait it off and try again later.
Yes, go to your scrapers and see how many api calls it’s done, then look at how many api calls the main account did. The api calls on the scraper should go up, so will the api calls on the main account. BUT the scraper will do a lot more api calls then the main account, so scraper API calls> main API calls.
1 Like