The USE ONLY EB option is unchecked on the scraper accounts. The EB scrape works when the account is logged in on the embedded browser. We don’t need to worry about this because Jarvee does an automatic EB login if the scraper account (which has ‘scrape with EB where possible’ checked) is needed for EB scraping and is not logged in on the EB.
1 Like
Ok tks. And how long are scrapers lasting for you?
You should just add them on Jarvee and making them valid. Don’t do any actions and wait, there is a high chance that they get banned without doing any actions, depending on where you buy them from.
I’m creating scrapers using high quality rotating residential proxies and only sms phone validation. When the scrapers are creating I add them to social profiles and copy the delay / api limit settings shared on this topic before starting them. They’re doing like 51 api calls maximum and they going again to phone validation. If I run the PV they go to 24h review and I lose the 0.20 cents I spent for that, so I prefer to create new, but they’ll die in less than 24hs again! Crazy! it wasn’t like that before.
I’m watching my scrapers to death massively since Jan 2nd. Does anybody is having the same problem?? I realized today this was checked when it wasn’t before:

That option was added in version 2.7.3.6 December 14th, initially it was not checked.
It was checked active in version 2.7.4,8 December 29th.
My scrapers have been OK this month so far, December was a lot worse.
Thanks @socialslacker. Can you tell me more about your settings? Api call limits, etc… Thanks in advance
Bro check out VOXI. Unlimited UK Instagram data for £10 per month. Thank me later!
I’m a relative noob, small scale scraper.
1 Main using EB only, on residential IP. F/UF, tagname method.
9 Scrapers @ 35 cent each, on DC proxies, one scraper per proxy.
In December proxies were burning fast, 24 hours to 5 days max. I tried to put in severe API limits and delays, it didn’t help, burned out the scrapers with lower limits. So I reset scrapers back to 300 API per day, 50 per hour. Decided to churn scrapers as needed. Things continued until January, when scrapers are lasting better.
Dec 13-29, lost 22 scrapers ie. average 1.3 per day.
Dec 30-04, lost 1 scraper, so average 0.16 per day
Since Dec 29th, my daily API calls have declined significantly, due to the new settings (scraping via EB). They are not hitting 300 per day, and I’m not noticing the intermittent delays caused by API settings any more.
The sample size is small & I don’t think the battle is won, but the temporary reprieve is enjoyable.
1 Like
Thanks bud! I was working with 2 scrapers per main, with low api calls limit (10/100). They were working fine till few days ago. Today I set a group of scrapers higher api limits. I will see how it goes! I will keep you updated.
The only recent change in my setup that I can identify is that EB scraping setting. It’s either that or the IG algorithm has a New Years party hangover.
2 Likes
are you sure that EB scraping is a thing? Someone recommended this a while ago earlier on this thread - I’ve tried to apply each suggestion as per below:
neither of these 2 settings actually made me use EB to scrape. I checked by logging in and having EB open on my screen when the scraper is doing it’s work. EB would not move at all not even once.
then I tried to put this on
which resulted in 0 scraping done throwing an error out.
If you open the EB, can you see it move and do stuff on the scraper? Cuz on my main acc where I follow/like I can see it actually doing those actions. And if so, is there another setting to make this work that I haven’t found yet?
I viewed the log files, and they do mention EB scraping, so it should be working. I have not monitored the EB browser for the scrapers so can’t confirm. I’ll watch those for a bit, will let you know what I find.
Two of the settings you posted are for the Main account (correct me if I’m wrong). The Scraper needs the following setting (the 2nd one you posted);
1 Like
Hey guys, I didn’t have need so far to use scraper accounts but now I do. I need some guide on setting them up.
So I have aged accounts with followers posts and all, they are like 5 years old. I want to use them as a scrapers for my main account. On my main account I just send DM, the problem is that I already have scraped list of users from before, but I can’t import them without getting api calls and getting account blocked for doing too much actions when I want to add users with method specificuser/username, I only have text file with usernames but I am getting some import error all the time, that file is not valid bla bla. Do you know how to fix this and import users there without doing api calls?
Or if that’s not possible, I will add scraper accounts to do those actions for main, but when I tried to add account it’s not getting valid, asking me to verify it trough email, but nothing happens, it just won’t get valid, when I click on browse, I can get inside with manual browsing with no problem, but when I try to confirm it in social profiles it’s asking me to click yes it’s me or asking for EV. How do I solve this? These accounts didn’t do any actions for some time, and they are all aged and warmed up, I am using proxy from highproxies (social media proxy) could that be the problem? Which proxy should I get for scrapers?
Thanks in advance
Scrape with EB is currently causing me to lose 20% scrapers per day so I stopped… still testing limits but at the moment API only with random actions is best
1 Like
You have good questions, I hope someone with more experience will help you.
So I have aged accounts with followers posts and all, they are like 5 years old. I want to use them as a scrapers for my main account.
If you like those accounts, be careful. Personally, I would only use disposable accounts for scraping. In my experience, they have a short life. Someone else may have a different idea about this.
I am using proxy from highproxies (social media proxy) could that be the problem?
I don’t think so, but you should try other proxies. When in doubt - test. I have some High Proxies, they work fine for scraping, but they are more expensive (and I didn’t enjoy my interaction with the support department), so I plan to terminate them.
Thanks bruce for the router help will keep trying.
I am doing the classic way, but scraping elsewhere an inputting manually. It does help with scraping via EB on the main, the scrapers tho… im have troubles with EV showing up. Use 4 g for main and DC for scrapers. Im just seeing where to set api limits for scrapers as i have ones doing 400+ a day and some go to EV at about 150-200
And from your earliest posts. Say mains running EBonly, there must be an account attached to the main to with API enabled to do scraping (scrapers). Or else if you run scraper with EB only it wont work, must have API connection.
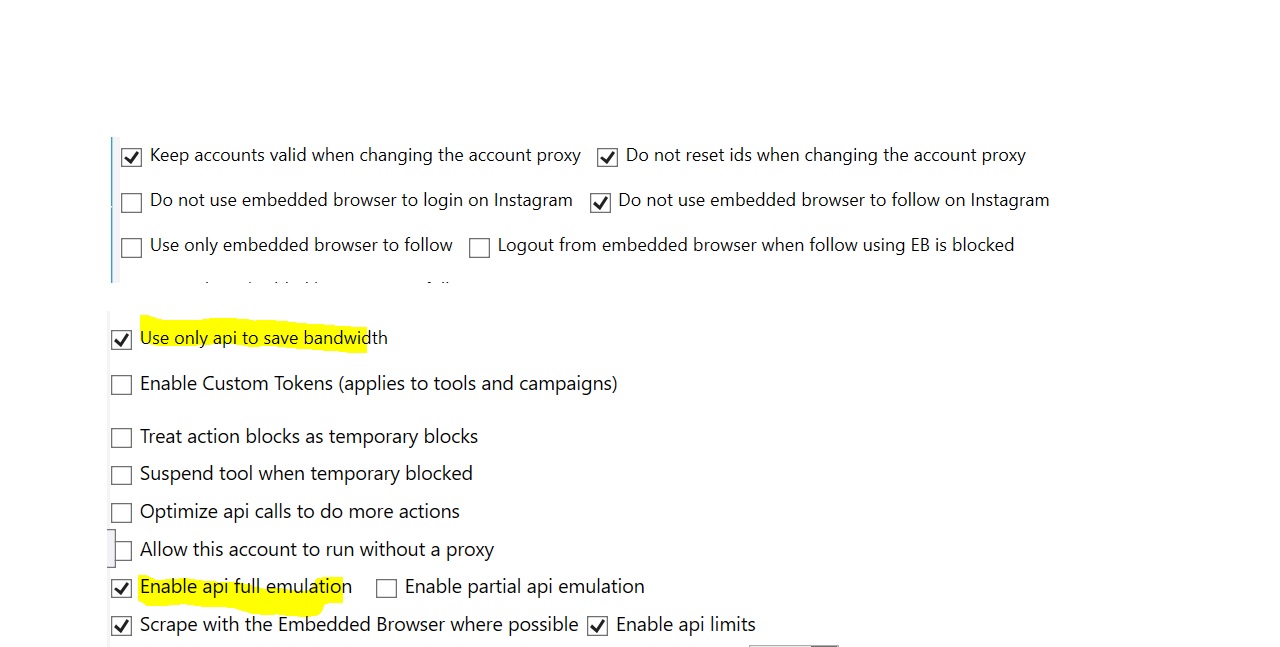
HI Kacper, wanted to test out - to scrape whenever possible with EB on scrapers.
Thanks for the previous settings, just a quick questions for the scraper:
Do you have the Enable Full API emulation checked?
Thanks
Thanks ossi
Thanks guys for the help earlier, just wanted to confirm:
I want scrapers to work with EB scraping too (on top of API) - do I have to change the yellow? is this correct settings?
When a scraper dies, most of us leave them alone and don’t bother recovering them. Ig then takes all the accounts that they sent a lock/pv… to that were not recovered, and then they have a lot, like a lotttt of data on how these accounts were running before they died. Then they see the common stuff all these accounts did and block them. The more scrapers people make, the more info IG has on scrapers, and the easier they will be able to take them down. We can always come up with new ways to automate stuff, but when everyone does the same thing it’s just telling IG to pay attention to us and do something about it.
5 Likes